
MongoDB存储引擎选择
- MongoDB存储引擎构架
插件式存储引擎, MongoDB 3.0引入了插件式存储引擎API,为第三方的存储引擎厂商加入MongoDB提供了方便,这一变化无疑参考了MySQL的设计理念。目前除了早期的MMAP存储引擎外,WiredTiger和RocksDB均 已完成了对MongoDB的支持,前者更是在被MongoDB公司收购后更是直接引入到了MongoDB 3.0版本中。插件式存储引擎API的引入为MongoDB丰富自己武器库以处理更多不同类型的业务提供了无限可能,内存存储引擎、事务存储引擎甚至 Hadoop在未来都有可能接入进来。

图1-1 MongoDB <= 2.6 存储引擎构架
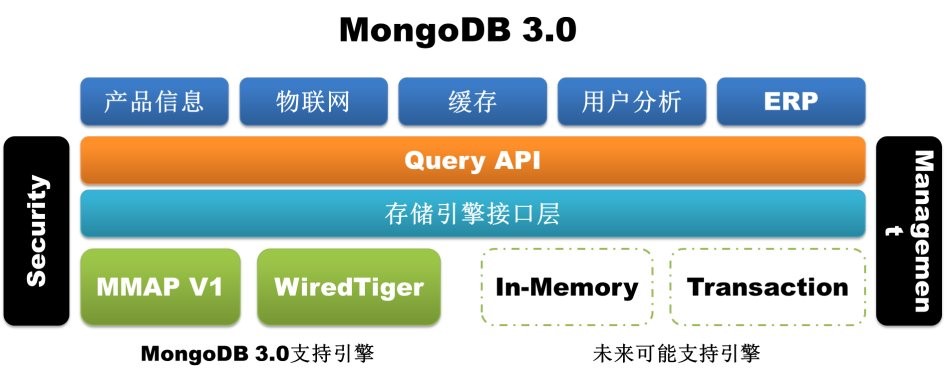
图1-2 MongoDB 3.0 存储引擎构架
- MongoDB存储引擎说明
- WiredTiger
如 果说插件式存储引擎API为MongoDB 3.0打造了一个武器库,那么WiredTiger绝对是武器库中第一枚也是最重要的一枚重磅炸弹。因为MMAP存储引擎自身的天然缺陷(耗费磁盘空间和 内存空间且难以清理,库级别锁),MongoDB为数据库运维人员带来了极大痛苦,甚至一部分人已经开始转向TokuMX,尽管后者目前也不甚稳定。意识到这一问题的MongoDB,做出了有钱任性的决定,直接收购存储引擎厂商WiredTiger,将WiredTiger存储引擎集成进3.0版本(仅在64位版本中提供)。那么这款走到聚光灯下的存储引擎究竟具备哪些值得期待的特性呢?
- 文档级别并发控制
WiredTiger 通过MVCC实现文档级别的并发控制,即文档级别锁。这就允许多个客户端请求同时更新一个集合内存的多个文档,再也不需要在排队等待 库级别的写锁。这在提升数据库读写性能的同时,大大提高了系统的并发处理能力。关于这一点的效果从监控工具mongostat就可以直接体现出来,旧版本 的监控指标会有locked db这一项(该项指标过高是mongo使用人员的一大痛点啊),而新版的mongostat已经看不到了。
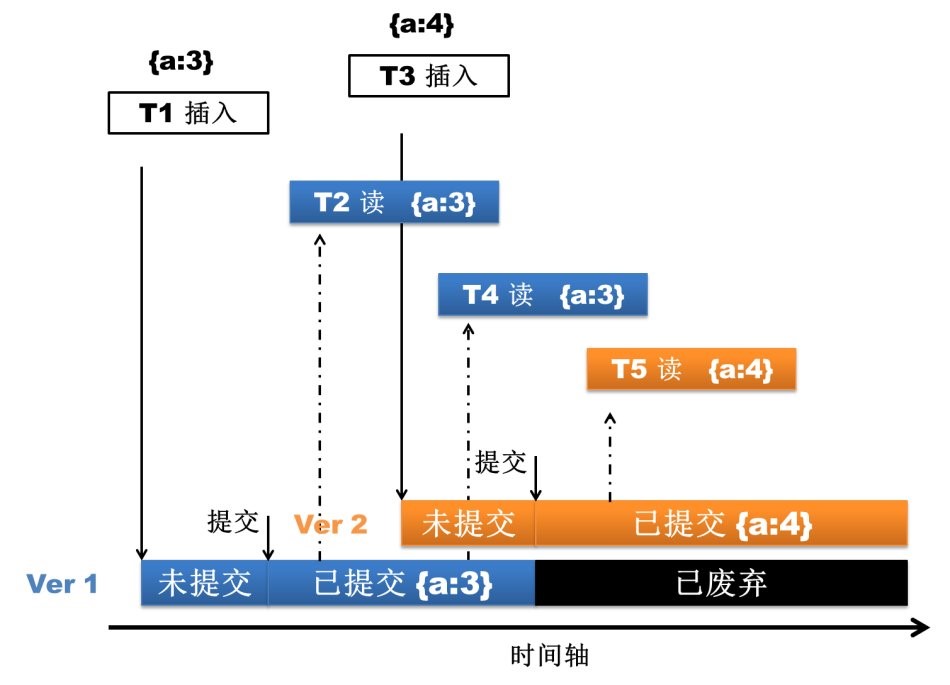
图2.1.1 文档级别并发控制
- 磁盘数据压缩
WiredTiger 支持对所有集合和索引进行Block压缩和前缀压缩(如果数据库启用了journal,journal文件一样会压缩),已支持的压 缩选项包括:不压缩、Snappy压缩和Zlib压缩。这为广大Mongo使用者们带来了又一福音,因为很多Mongo数据库都是因为MMAP存储引擎消 耗了过多的磁盘空间而不得已进行扩容。其中Snappy压缩为数据库的默认压缩方式,用户可以根据业务需求选择适合的压缩方式。理论上来说,Snappy 压缩速度快,压缩率OK,而Zlib压缩率高,CPU消耗多且速度稍慢。当然,只要选择使用压缩,Mongo肯定会占用更多的CPU使用率,但是考虑到 Mongo本身并不是十分耗CPU,所以启用压缩完全是值得的。
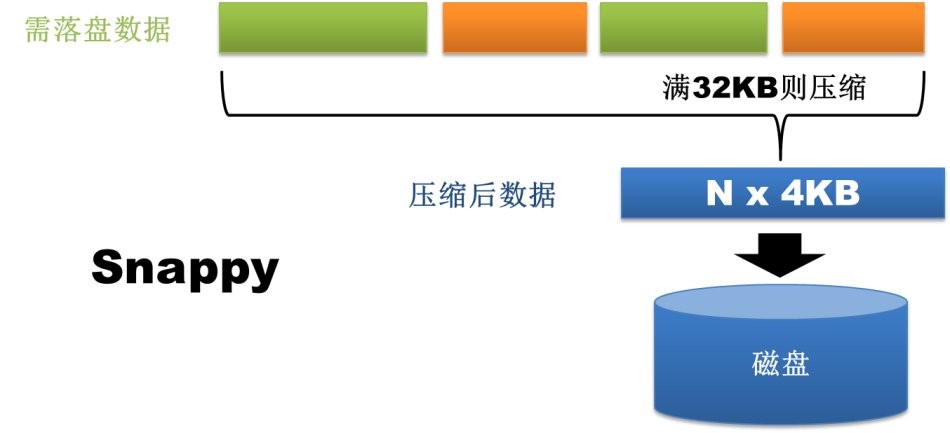
图2.1.1-1 磁盘数据压缩 snappy
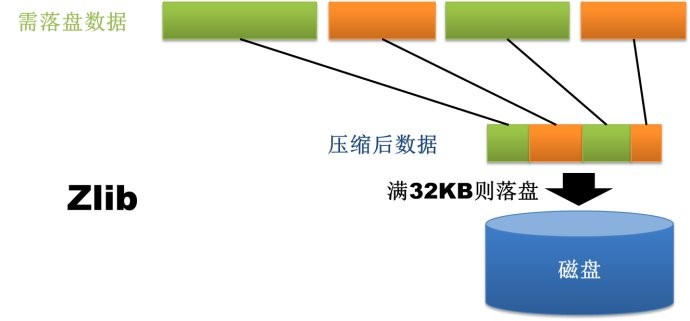
图2.1.1-1 磁盘数据压缩 zlib
- 存储方式改变
此 外,WiredTiger存储方式上也有很大改进。旧版本Mongo在数据库级别分配文件,数据库中的所有集合和索引都混合存储在数据库文件中,所以即 使删掉了某个集合或者索引,占用的磁盘空间也很难及时自动回收。WiredTiger在集合和索引级别分配文件,数据库中的所有集合和索引均存储在单独的 文件中,集合或者索引删除后,对应的存储文件随即删除。当然,因为存储方式不同,低版本的数据库无法直接升级到WiredTiger存储引擎,只能通过导 出导入数据的方式来实现。
- 可配置内存使用上限
WiredTiger 支持内存使用容量配置,用户通过storage.wiredTiger.engineConfig.cacheSizeGB参数即可 控制MongoDB所能使用的最大内存,该参数默认值为物理内存大小的一半。这也为广大Mongo使用者们带来了又一福音,MMAP存储引擎消耗内存是出 了名的,只要数据量够大,简直就是有多少用多少。
- MMAPv1
MongoDB 3.0出了引入WiredTiger外,对于原有的存储引擎MMAP也进行了一定的完善,该存储引擎依然是3.0版的默认存储引擎。遗憾的是改进后的 MMAP存储引擎依旧在数据库级别分配文件,数据库中的所有集合和索引都混合存储在数据库文件中,所以磁盘空间无法及时自动回收的问题如故。
- 锁粒度由库级别锁提升为集合级别锁
这在一定程度上也能够提升数据库的并发处理能力。
- 文档空间分配方式改变
在 MMAP存储引擎中,文档按照写入顺序排列存储。如果文档更新后长度变长且原有存储位置后面没有足够的空间放下增长部分的数据,那么文档就要移动到文件 中的其他位置。这种因更新导致的文档位置移动会严重降低写性能,因为一旦文档发生移动,集合中的所有索引都要同步修改文档新的存储位置。
MMAP 存储引擎为了减少这种情况的发生提供了两种文档空间分配方式:基于paddingFactor(填充因子)的自适应分配方式和基于 usePowerOf2Sizes的预分配方式,其中前者为默认方式。第一种方式会基于每个集合中文档更新历史计算文档更新的平均增长长度,然后在新文档 插入或旧文档移动时填充一部分空间,如当前集合paddingFactor的值为1.5,那么一个大小为200字节的文档插入时就会自动在文档后填充 100个字节的空间。第二种方式则不考虑更新历史,直接为文档分配2的N次方大小的存储空间,如一个大小同样为200字节的文档插入时直接分配256个字 节的空间。
MongoDB 3.0版本中的MMAPv1抛弃了基于paddingFactor的自适应分配方式,因为这种方式看起来很智能,但是因为一个集合中的文档的大小不一,所 以经过填充后的空间大小也不一样。如果集合上的更新操作很多,那么因为记录移动后导致的空闲空间会因为大小不一而难以重用。目前基于 usePowerOf2Sizes的预分配方式成为默认的文档空间分配方式,这种分配方式因为分配和回收的空间大小都是2的N次方(当大小超过2MB时则 变为2MB的倍数增长),因此更容易维护和利用。如果某个集合上只有insert或者in-place update,那么用户可以通过为该集合设置noPadding标志位,关闭空间预分配。
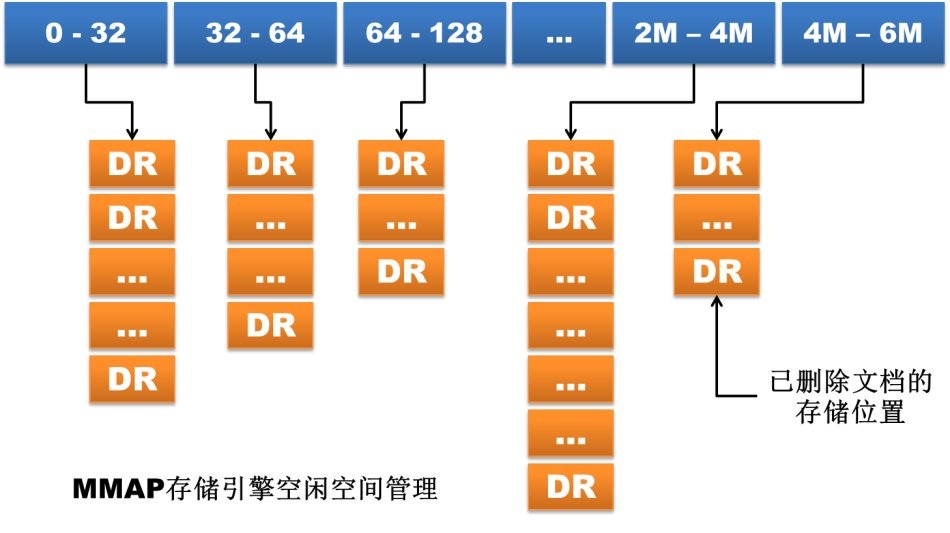
图2.2.2 存储引擎空间管理
- MongoDB存储引擎性能对比
- 官方数据,基于YCSB测试,WiredTiger引擎
YCSB被一些机构用来作为对几个不同数据库的性能测试的一个工具。YCSB功能是相当有限的,并不一定能够告诉你所有你想了解的关于你应用程序性能方面的信息。当然,YCSB还是相当流行的,并且MongoDB和其他一些数据库系统的用户也对此比较熟悉。
- 并发量
100%写场景:在YCSB测试中, MongoDB3.0在多线程、批量插入场景下较之于MongoDB2.6有大约7倍的增长。
95%读取和5%更新的场景: WiredTiger 有4倍多的吞吐量。相比于纯插入场景,性能提升没有那么显著,因为写操作只占所有操作的5%。在MongoDB2.6中,并发控制是在数据库级别,而且写会阻塞读操作,从而降低总体的并发量。通过这次测试,我们看到MongoDB 3.0更加细粒的并发性控制明显提高了总并发量。
读写操作平衡的场景: MongoDB3.0有6倍的并发率。这比95%读 的4倍提高要好一些,因为这里有更多的写操作。
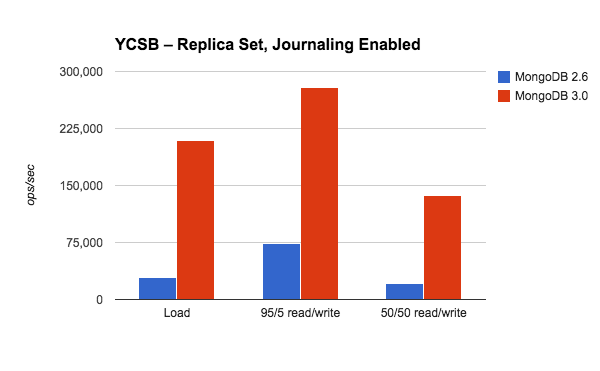
图3.1.1 并发量
- 响应延迟
在性能测试中仅仅监测并发量是不够的,还要考虑操作的响应延迟 。对许多操作的响应延迟做一个平均得来的平均响应延迟值不是一个最好的度量指标。对于想要系统有持续良好、低延时体验的开发者来说,他们更关注在这个系统 中效能最低的操作。 高延时查询通常用95th和99th百分位数来衡量 – 95th 百分位数表示这个数值(响应延迟)比95%的其他操作都要糟糕(慢)。(有人可能会觉得这种衡量不够准确: 因为很多网页请求会使用几百个数据库操作, 那么很可能绝大部分用户都会经历到这些99th百分位数的慢响应延迟 )
在读操作响应延迟上看到在MongoDB2.6和MongoDB3.0之间的差别是非常微小的,读操作响应延迟很稳定的保持在1ms或者更少的数值内。然而更新操作响应延迟则有相当大的区别 。
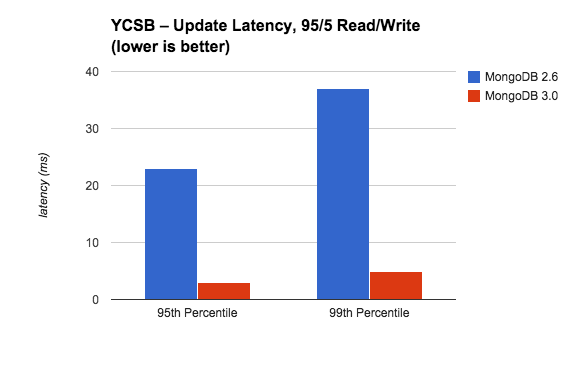
图3.1.2-1响应延迟,读密集型
在这里我们通过读密集型的工作负荷来比较更新响应延迟的95th和99th百分位数 。在MongoDB3.0中更新延时显著改善了,在95th和99th百分位数中几乎减少了90%。这很重要,提高并发量不应该以更长的延时为代价,因为 这将最终降低应用程序 的用户体验。

图3.1.2-1响应延迟,平衡型
在平衡的工作负荷下,更新延迟仍然保持在较低的水平 。在95th百分位数,MongoDB3.0的更新延迟比MongoDB2.6几乎低90%,而99th百分位数则低80% 。这些改善可以给用户带来更好的使用体验,更加可预测的性能。
我们相信这些针对并发量和响应延迟的测试证明了MongoDB在写性能上有了显著的提高。
- 提供充足客户端能力
大多数数据库都是为多线程客户端设计的 。通过逐步增加线程数来找到最佳的数量 – 增加更多线程直到你发现并发率停止上升或者响应时间在增加。
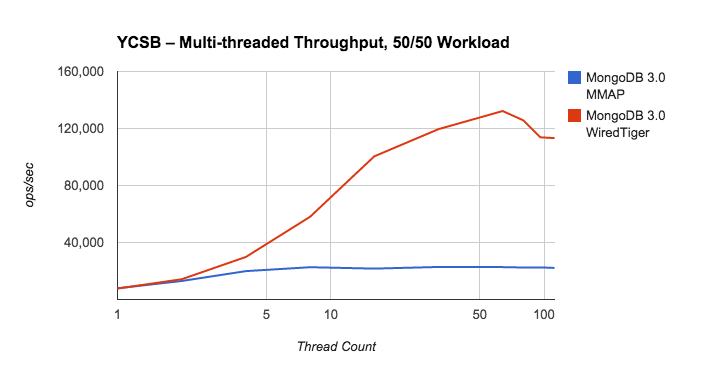
图3.1.3-1多线程MMAP、WiredTiger吞吐量对比
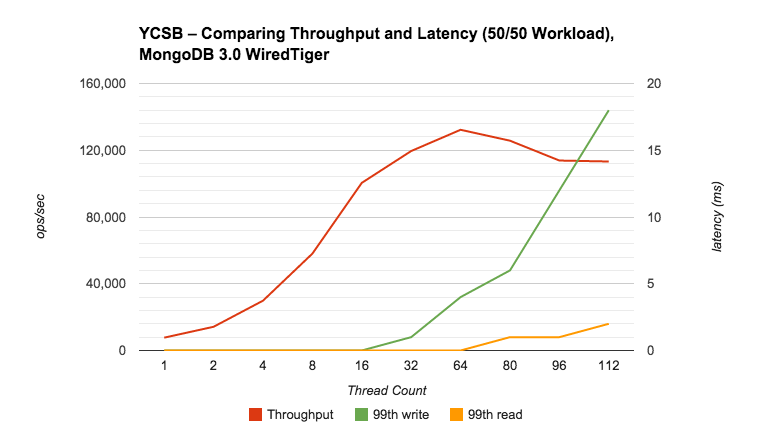
图3.1.3-1 WiredTiger吞吐量延迟对比
- 实际测试
时间关系,本人未做相关测试,网上收录部分测试数据;
- 案例一
公司某个APP应用的数据库已 经实现了日志与业务的垂直分割,将原有的一套RAC,拆分成两套,目前数据库暂时还比较稳定,服务器负载也在正常范围内,但是现有用户数450万,日活跃 用户达到100万,每日日志产生1000万条记录,100G的数据量,而目标用户数接近1800万,预估届时的每日数据库将达到6000万/条,且需要满 足单条记录查询的需求,计划采用MongoDB来替代ORACLE RAC,现测试MongoDB WiredTiger引擎与MMAPv1引擎的写入对比。
测试场景:插入1000万条数据的时间消耗对比;
测试结果:MongoDB MMAPv1写入配置:1000万条数据写入花费了12分钟28秒;MongoDB WiredTiger写入配置:1000万条数据写入花费了10分3秒。
- 案例二
某项目在设计初期使用了mongodb2.6,由于开发设计失误在mongodb中使用了一个很大的数据。而该业务每天需要全亮更新每一个文档,也就是更 新数组字段,这致使在ssd上依然出现了性能问题,而由于该项目已经不再更新处于维护节点并且之前的开发已离职,导致无法通过修改业务逻辑变更数据结构来 调优。
将其迁移到mongodb3.0后数据提及从202G降低到36G,同时更新性能提高五倍,完美解决了性能问题。
- 案例三
Mongdob3.0.2的一个项目使用汇报:
之前使用18分片的mongoS集群,用于业务的统计分析,比如404、503、请求量以及网址请求次数等等。
mongodb的使用场景为:
- 每秒写入2万条数据,其中insert和update比例为3:7,全部使用upsert方法
- 全部查询均为统计类查询,用于画图
在今年年初由于写入并发量不断增长到3万条每秒,导致出现了严重的性能问题,现象为:
- 写入队列积压,每天大概积压80G数据,数据延迟写入22小时,也就是现在的数据,22小时候才能看到
- 查询基本不可用,无法在页面通过统计绘图了
在4月26号升级到了3.0.2,结果如下:
- 写入队列无任何积压,实时写入
- 查询速度暴快,绘图秒出
- 分片减少了一半,从18个变为9个,每个分片使用2块独立的ssd,等于0为我们省下了18块ssd
- 数据总体积的变化:从3T变成了不到600G
- 慢更新消失了(500ms以上的操作会记录日志)
- 总结
从官方数据和实际使用效果来说,WiredTiger引擎总体上胜出MMAPv1,不论从内存使用效率和存储空间使用效率,还是其写入更新效率,所以在选用MongoDB3.0以上版本时建议还是采用WiredTiger引擎。
但是需要注意一下几点:
首先其在Windows上的性能指标不如Linux,所以搭载服务器最好选用Linux系;
其次Journal 默认不会即时刷盘,系统宕机会丢失最多100MB Journal数据;
再有其不提供32位 支持;